A likely-correct list
Creating a likely-correct list component with formal and semi-formal methods to support rapid iteration
-
Table of contents
- Introduction
- Methodology
- Creating a likely-correct list
- Analysis
- Conclusion
- Resources
- About the author
- Credits
- Appendix 1 — The methods
- Appendix 2 — The process and the roles
- Appendix 3 — Concept definitions with AI
We need this here because of Tufte ...
-
Updates
- Feb 24, 2025 — Font family updated from serif to sans-serif
We need this here because of Tufte ...
Introduction
Two emerging trends are reshaping software architecture and development practices:
-
Applied category theory
- Kris Brown: Scientific and software engineering examples of applied category theory
- E.Subrahmanian & Y.Keraron: Engineering practice and the potential role of CT in systems engineering
- Categories for the Working Hacker, by Philip Wadler
- Category Theory, The essence of interface-based design - Erik Meijer
- Programming with Math | The Lambda Calculus
-
A new kind of formalism
We do not aim to achieve full formal verification, but instead emphasize automation, usability, and the ability to continually ensure correctness as both software and its specification evolve over time
Using tools to help us think about the design of systems at the design stage can significantly increase the speed of software development, reduce risk, and allow us to develop more optimal systems from the beginning
These new methods are more rigorous than today’s informal practices, yet less costly to adopt than classic formal methods, like theorem proving.
To create a likely-correct list, this study integrates a formal method and two semi-formal methods into two software engineering processes:
- Information Architecture (IA) design dealing with structure (ontology, taxonomy) and behavior(choreography)
- Software development life cycle, dealing with understanding, design, implementation and verification.
The emphasis is put on the early, generic phases—understanding, architecture and design—rather than implementation or verification, which are more subjective phases.
The result should provide software architects and senior engineers with methods to formalize software structure and behavior, leading to better implementation.
And in a future stage, should provide AI/ML practitioners with insights to combine generative AI’s speed with the rigor of these new techniques to produce better software, faster.
Methodology
Before presenting the methodology, it’s essential to clarify three key concepts: formalism, correctness, and cost. These concepts provide the necessary context for this work.
| Method | Correctness | Cost |
|---|---|---|
| Formal | Provably correct | Expensive |
| Semi-formal | Likely-correct | Affordable |
| Informal | Maybe correct | Minimal, but it's a debt |
The methodology of this study is a combination of semi-formal and formal methods; therefore, the end result is likely-correct rather than provably-correct.
Some methods are well-known but underused in software engineering, such as the scientific method, while others are entirely new, including ontology logs from category theory.
Each method is useful on its own. When combined into a process or methodology, the benefits ideally add up.
| Step | Aspect | Method | Formalism |
|---|---|---|---|
| Understanding | Scientific inquiry |
Scientific method Ontology logs |
Semi-formal Formal |
| Design / Structure | Ontology, taxonomy | Ontology logs | Formal |
| Design / Behavior | Choreography |
Concept design Finite-state machines |
Semi-formal Formal |
| Implementation and verification | - |
Stately.ai/XState Property-based testing |
Semi-formal Semi-formal |
A brief introduction of the methods is available in the Appendix 1 while Appendix 2 provides context and further insight into the process.
Creating a likely-correct list
The objective of this study is to create the first iteration of a likely-correct list, ensuring it is well-prepared for subsequent iterations.
The focus is on understanding and design, aiming to achieve a solid starting point. Once this foundation is established, the process continues with implementation and verification.
A likely-correct list must have a likely-correct structure and a likely-correct behavior. Additionally, to make the list user-facing, its behavior must be studied within the UX/UI context.
The ontology log ensures a correct structure, concept design integrates the structure into the user interface context, and finite state machines ensure correct behavior.
The implementation and verification follows the author’s preferred stack: React, TypeScript, and XState. However, others may choose different tools, so the focus is on the process rather than the specific technologies used.
What’s a list?
As a software architect and casual internet user, the author often wonders about the idea that lists form the backbone of many applications—particularly user-facing ones.
When browsing random websites, web apps, or mobile apps, we see data displayed as lists; when interacting with user interfaces, we mostly engage with lists.
-
Screenshots of random websites where lists are highlighted
Hacker News 
MIT CSAIL 
Github 
ChatGPT 
Discord -
Common interactions mapped to list operations
This is a list of interactions and how they relate to lists. It was generated by an LLM, it might be inaccurate, but delivers the point.
Common interactions mapped to list operations Operation Relation to Lists Like/React Performed on an item in a list (e.g., a post, comment, or review). Comment/Reply Adds an item to a list of comments or threads. Flag/Report Targets a specific item in a list for attention. Share Applies to an item in a list (e.g., a post or document). Save/Bookmark Adds the item to a personal list of saved content. Rate/Review Associates feedback with an item in a list, often visible alongside other ratings. Select/Highlight Chooses one or multiple items from a list for further actions. Expand/Collapse Reveals or hides details for a specific item in a list or nested sub-list. Filter Refines the visible items in a list based on criteria. Sort Rearranges the items in a list by specified attributes. Pin/Unpin Moves an item to the top of a list or returns it to its original position. Add/Create Appends a new item to a list (e.g., tasks, files, posts). Edit/Update Modifies an existing item in a list. Delete/Remove Removes an item from a list. Duplicate/Fork Creates a new item based on an existing one in a list. Invite/Add People Adds a person to a list of participants or members. Follow/Unfollow Subscribes/unsubscribes to updates from an item in a list (e.g., channels, users). React to Comments Adds a reaction to an item in a comment list or thread. Assign/Delegate Associates a list item (e.g., a task) with a person. Acknowledge/Mark as Read Updates the status of an item in a list of notifications or alerts. Track/Subscribe Adds an item to a personal list of tracked or subscribed content. Mute/Unmute Updates the status of an item in a list (e.g., muting a channel or thread). Search Queries a list of items to find specific results. Tag/Label Organizes items by adding metadata, creating categorized sub-lists. Explore/Discover Presents curated or trending lists for browsing. Upload/Attach Adds files or assets to a list associated with a task, post, or message. Batch Operations Applies actions to multiple selected items in a list. Archive/Restore Moves an item between active and archived lists.
Given that lists are everywhere, the next logical step is to ask:
Can we create a list component upon which we can easily build user interfaces?
Such a list component must be generic, universal, and usable in any scenario.
Since this is a vague requirement—it's impossible to anticipate all possible or future use cases—we can do two things:
- Capture the core essence of the list upfront and implement a few key scenarios
- Deliver a solution that is both understandable and extendable, enabling rapid iteration
To approach this systematically we employ the scientific method to guide the entire process—from understanding to implementation and verification.
| Step | Outcome |
|---|---|
| Observation | User interfaces are built on lists |
| When interacting with user interfaces we mostly interact with lists | |
| Data | Screenshots of several, random websites and apps, each featuring multiple lists |
| The list of common UI operations on web apps | |
| Questions | Can we have a list component upon which we can easily build user interfaces? |
| Hypothesis | Maybe, with a good start and later through community effort supported by rapid iteration |
| Experiment | Designing a likely-correct list |
| Implementing a likely-correct list | |
| Analysis | A sound foundation capable for rapid iteration |
| Conclusion | The ultimate goal is diagrams as code |
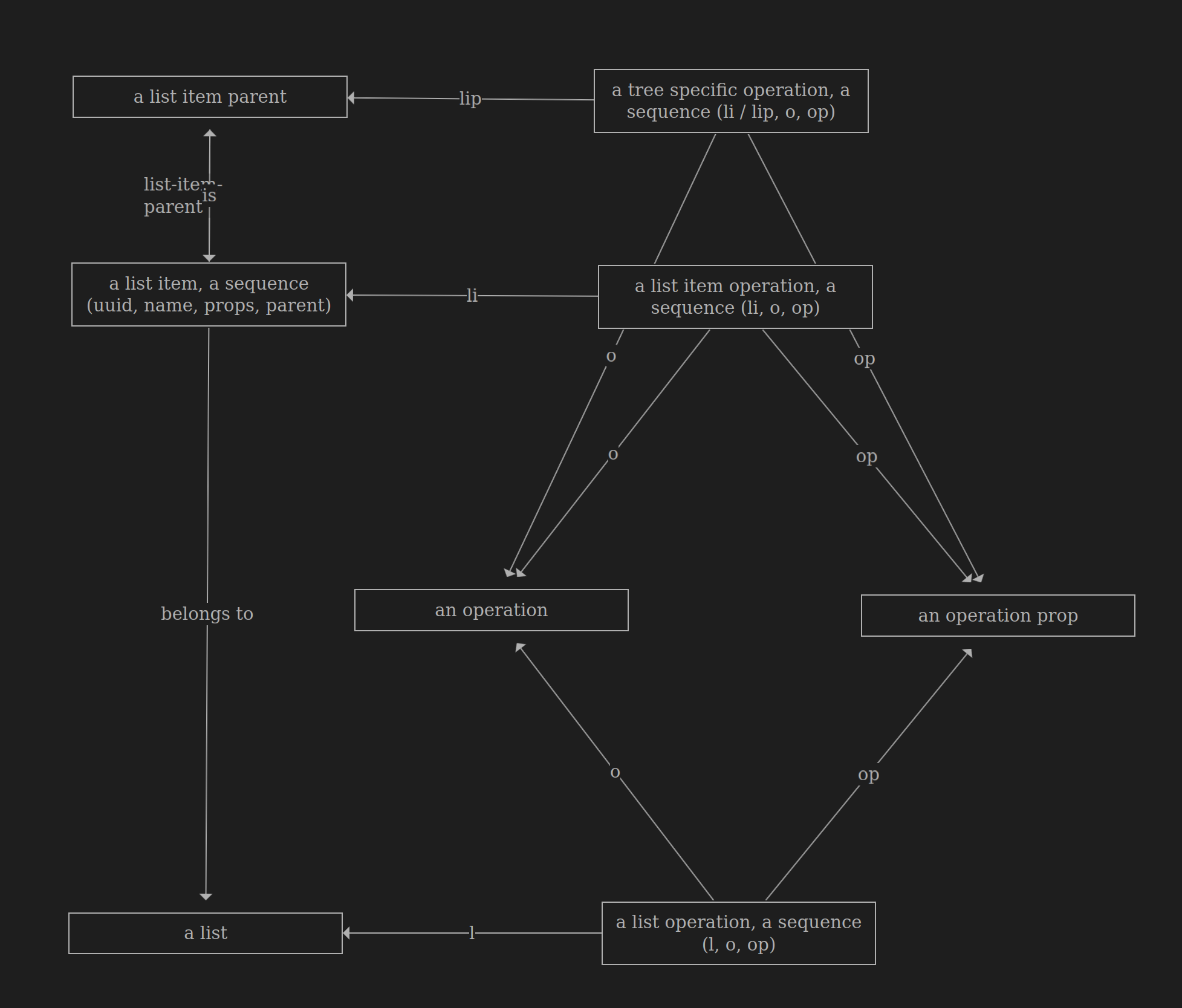
Provably-correct structure with ologs
Ologs provide a provably-correct understanding of a concept.
Studying the concept of lists with ologs, results in the author’s worldview, in the following diagrams:
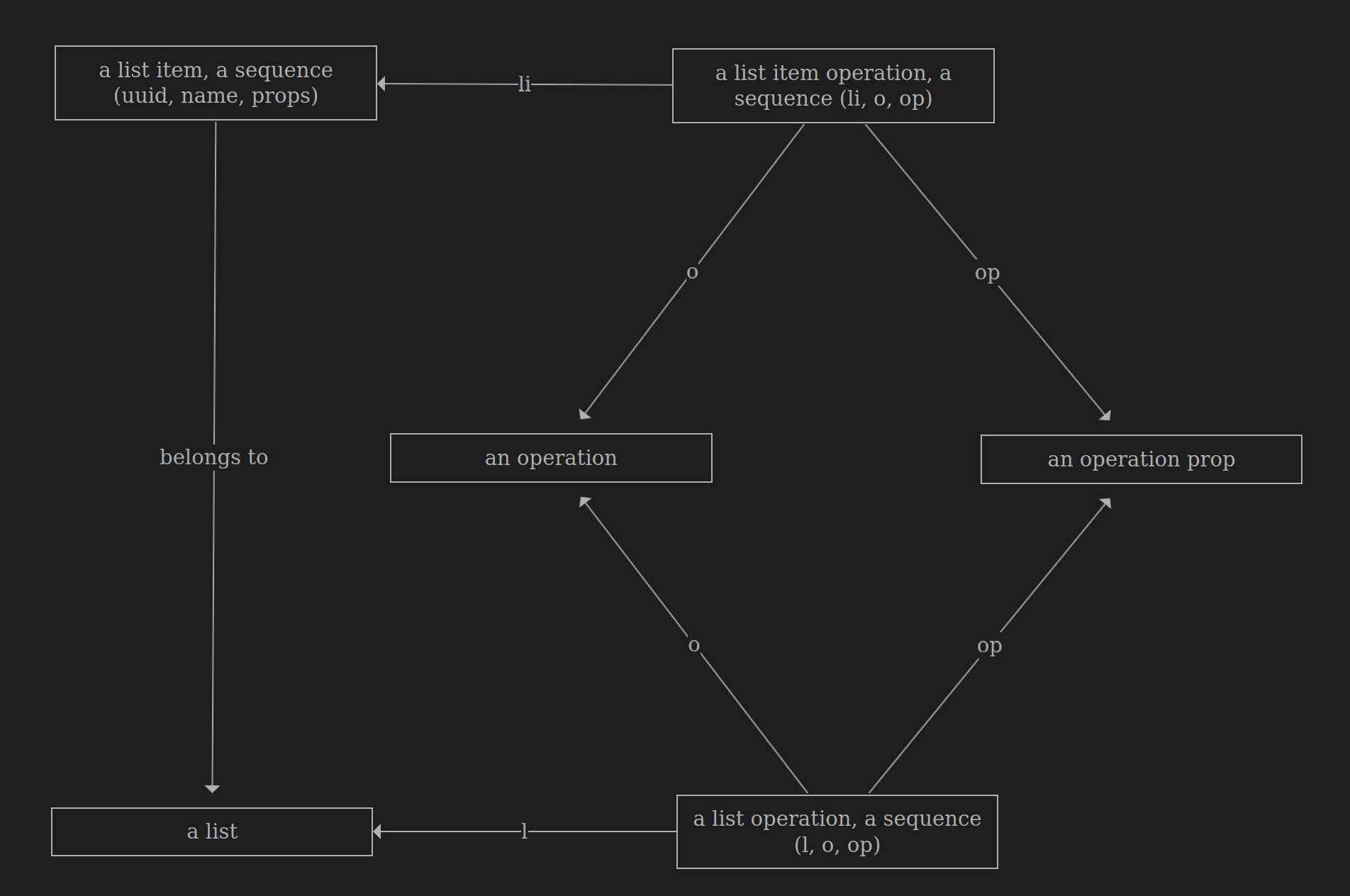
-
More diagrams
The relationship between list items and list 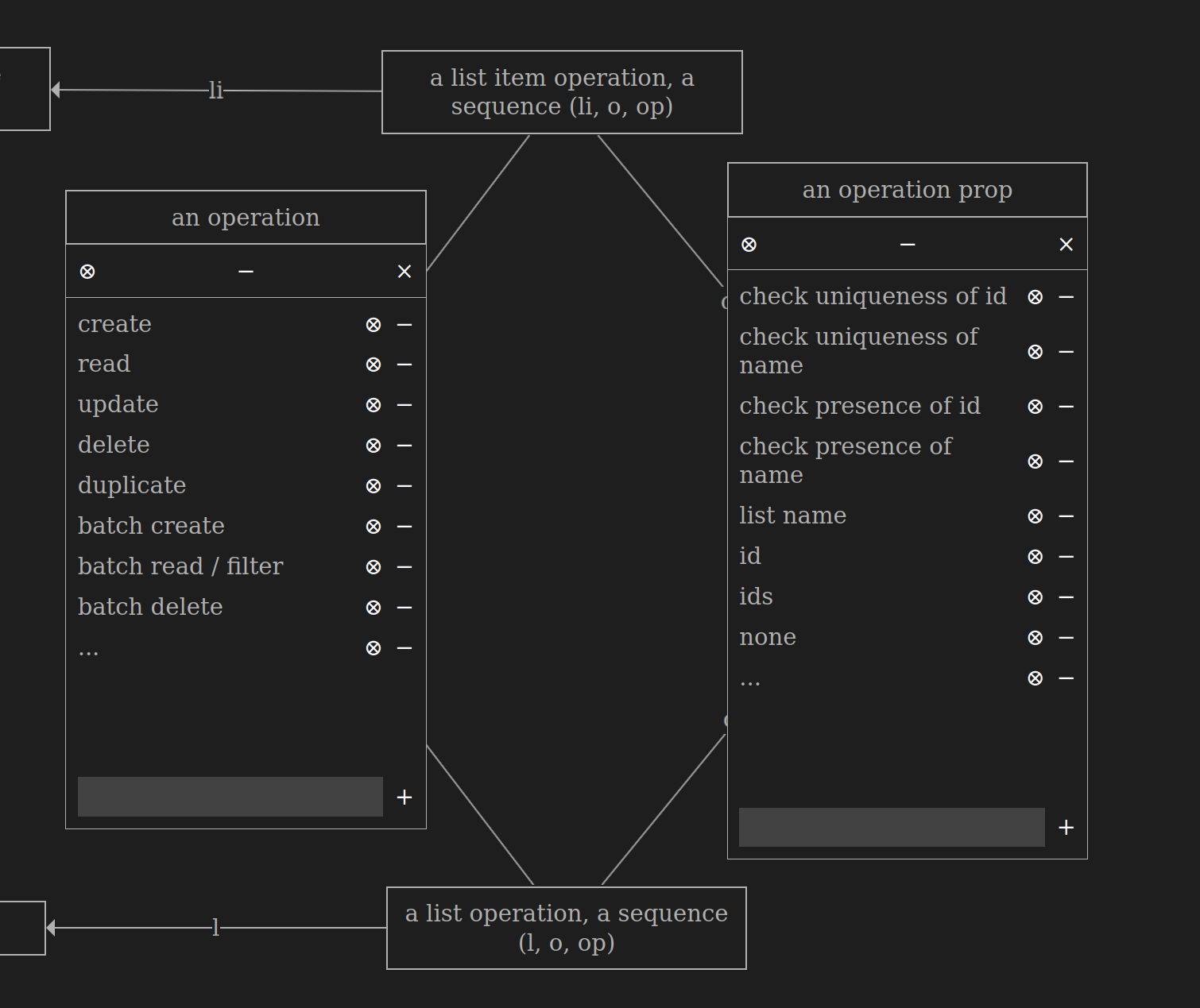
Operations and operation props 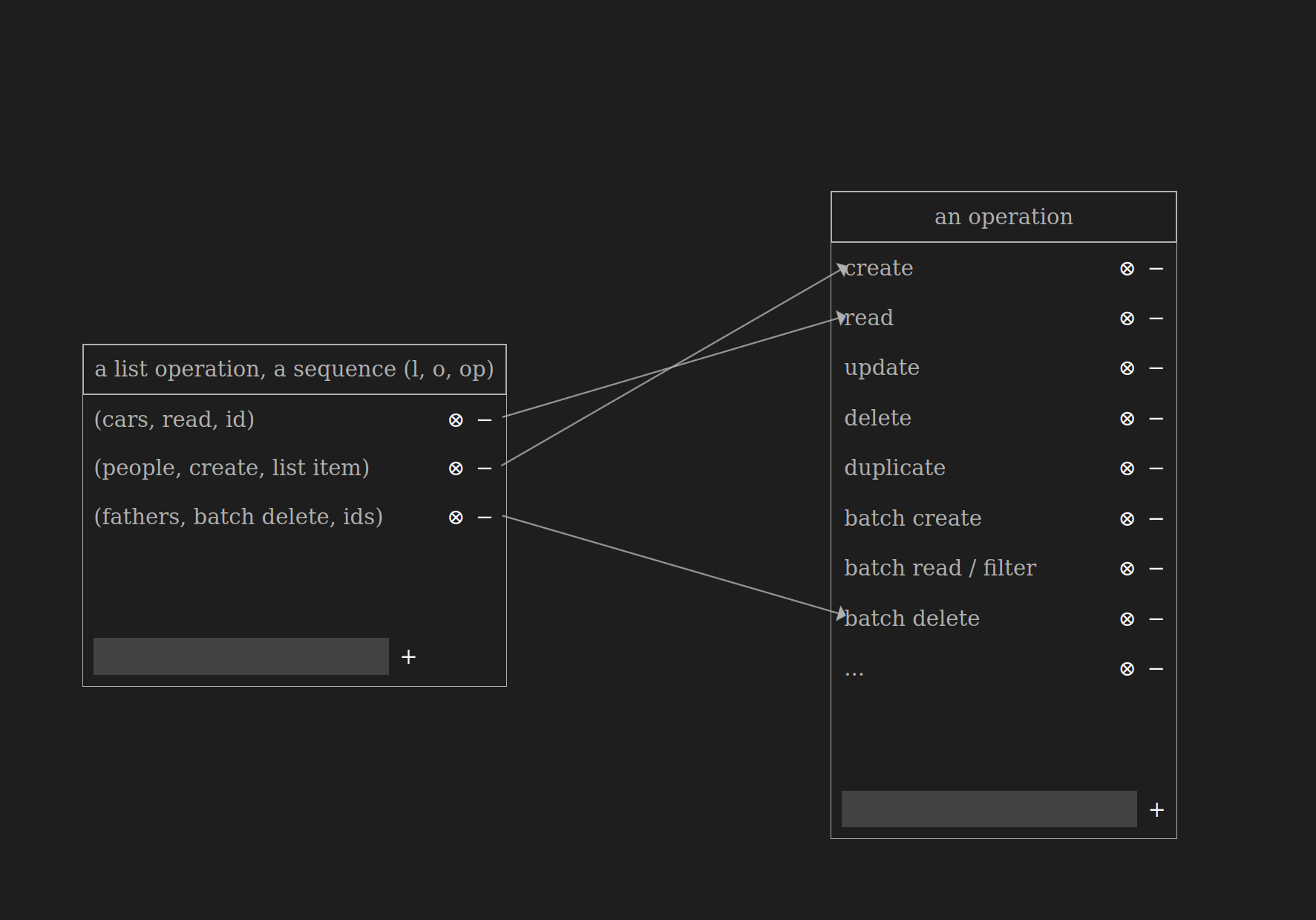
List operations 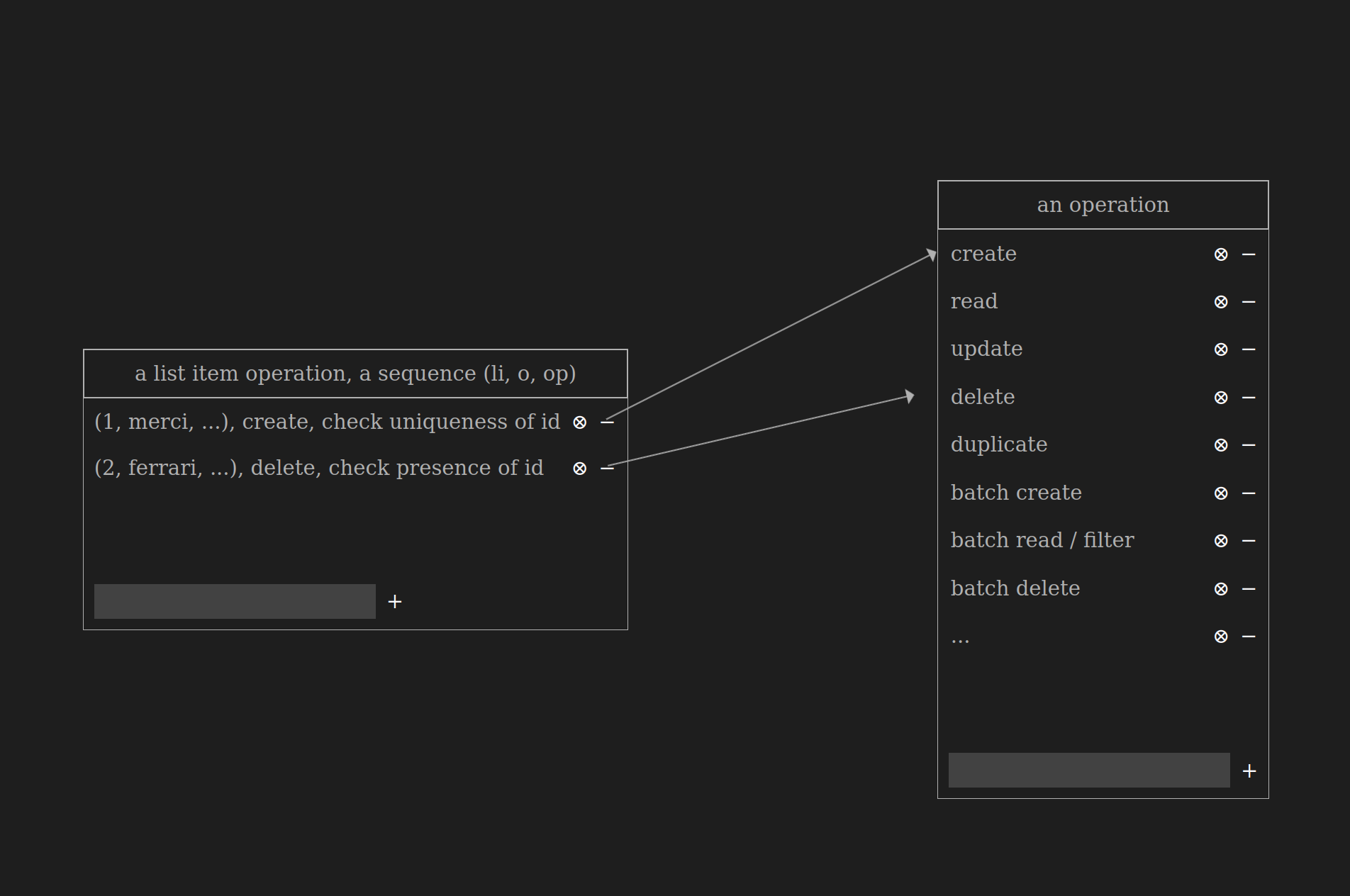
List item operations
The olog provides a clear and sound structure: a list, a list item, operations, operation properties, and specific operations for lists and list items.
Beyond structure, ologs convey facts—the relationships between elements, represented by the arrows connecting the boxes.
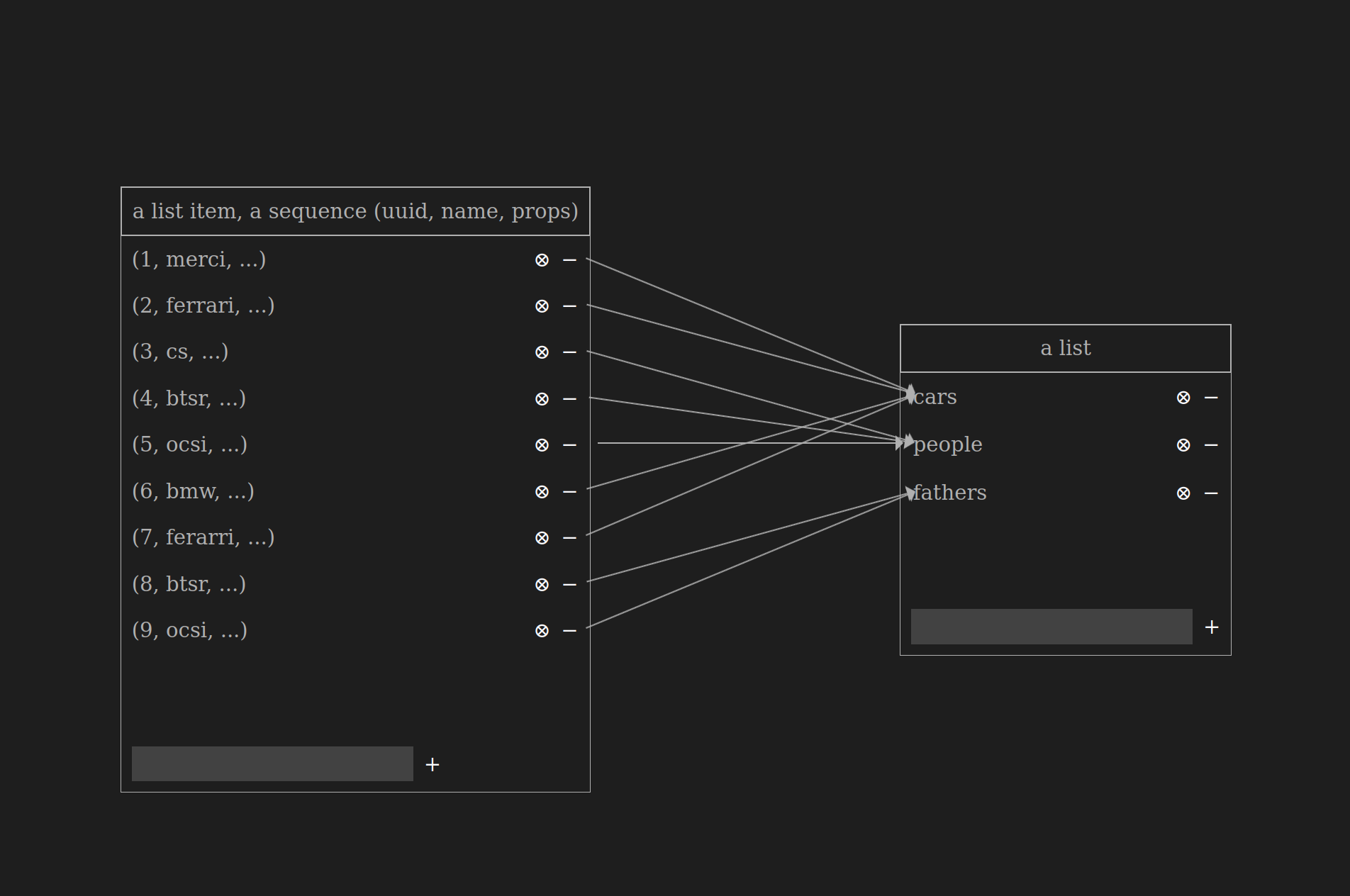
The list olog states:
-
There are multiple lists
-
Like
cars,people,fathers, …
-
Like
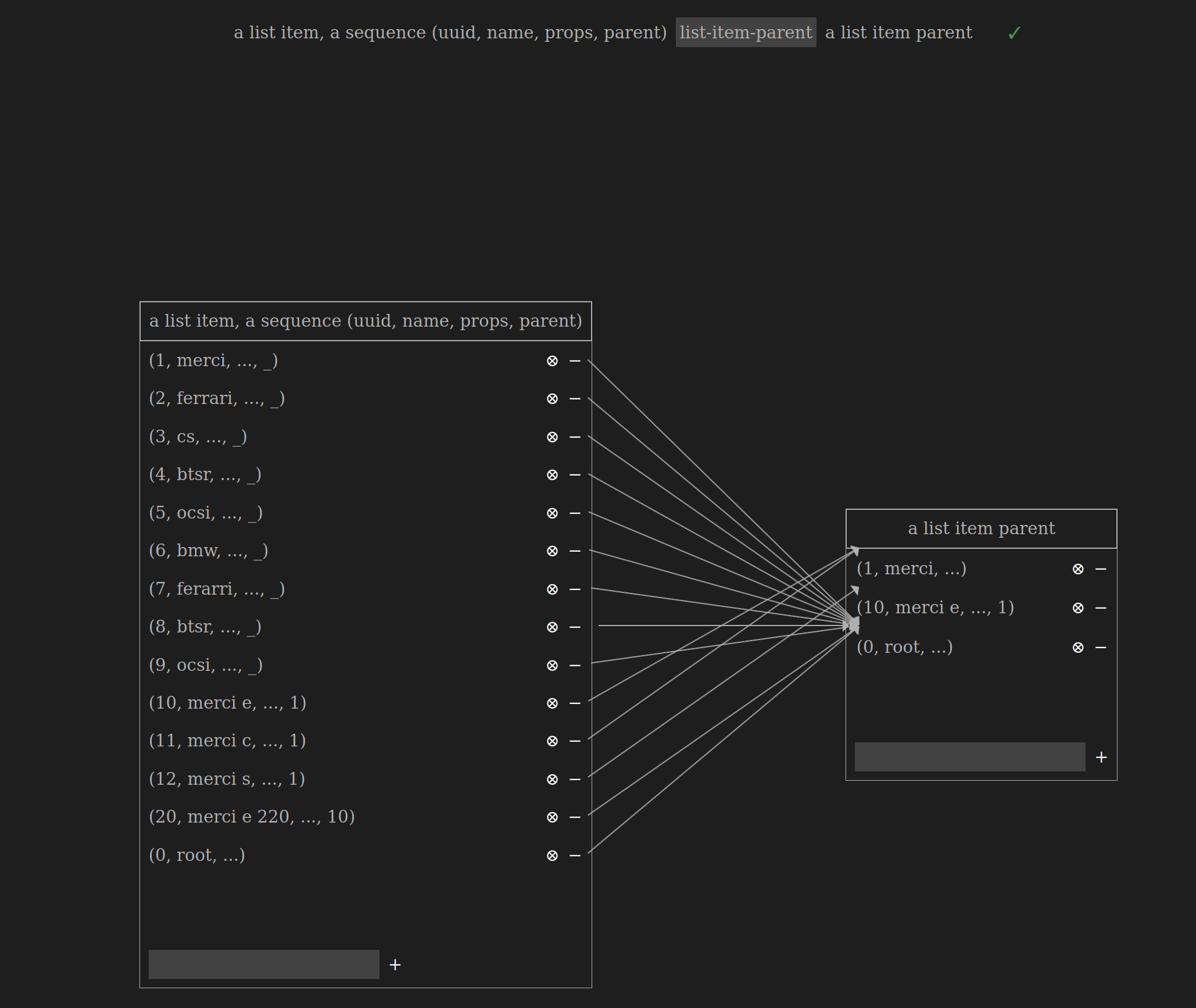
-
A list item always belongs to a single list
-
A list item belongs to a single list
-
The
ferrarilist item can’t belong to bothcarsandpeopleat the same time, due to the nature of ologs
-
The
-
A list item cannot exist on its own without being associated
with a list
-
If we add a new list item
(10, bob)and don’t associate with a list (peopleorfathers) then thea list item belongs to a listrelationship breaks due to the nature of the ologs
-
If we add a new list item
-
A list item belongs to a single list
-
A list item can share the same name as another list item
-
A list item named
ferrarican belong to bothcars(Ferrari Testarossa) andpeople(Enzo Ferrari)
-
A list item named
-
List items are unique
-
By adding
uuidto list items we are able to differentiate list items with the same name
-
By adding
-
Operations have a name (
an operation) and props (an operation prop)-
For example, the
createoperation has thecheck uniqueness of idprop -
For example, the
readoperation has theidprop
-
For example, the
-
Lists and list items have their own set of operations
-
For example, the
duplicateoperation on a list item creates a new item with the same name but assigns it a differentid -
The
duplicateoperation on a list creates a new list with the same name but a differentid, and it also duplicates all the items within the list
-
For example, the
We need this here because of Tufte ...
User-facing context with concept design
While ologs formalize the structure of a concept, concept design investigates how a concept behaves in an user-facing environment.
Concept design uses constructs such as concept, action, app, and atomic synchronization. Let’s explore how these map to the olog.
The list olog provides seven structures, four of which are related to operations: operation, operation properties, list operations, and list item operations. These structures map to actions and synchronizations in concept design.
What’s left is the list and
list item structure which may map to
concepts and/or apps.
The olog suggests that list and
list item could be considered two distinct entities:
- They have different operations
- There are operations that requires synchronization, which is characteristic of scenarios involving apps and multiple concepts
This introduces uncertainty: what was initially intended as a single concept now appears to evolve into two distinct entities.
In an attempt to resolve this uncertainty, and after further careful
examination of the operations and their properties, a
list item seems to be a concept in its own right, as it
typically involves CRUD-like operations or regular actions in concept
design.
concept ??? # We don't know the exact name yet
purpose
to provide operations on a collection
state
items: set Item
actions
create (i: Item)
read (id: Text)
update (id: Text, i: Item)
delete (id: Text)
duplicate (i: Item)
batchCreate (i: Item[])
batchRead (p: predicate) # Filter
...
principles
??? # This will be tackled once the state and actions are defined
A list, on the other hand, tends to involve sync-like
operations and appears to function as an app:
app ??? # We don't know the exact name yet
includes
... # Some lists
syncs
duplicateList (source: List)
source.duplicate
source.items.duplicate
duplicateListItems (source: List, predicate: function, destination: List)
source.items.filter(predicate)
destination.items.batchCreate
moveListItems (source: List, predicate: function, destination: List)
source.items.filter(predicate)
source.items.batchDelete
destination.items.batchCreate
To get a better picture—and in accordance with the Rule of Three—we need a third use case. Let this be the tree, a close relative of the list.
Then, we will have:
- A concept, with CRUD-like operations
- A concept or an app, with some operations requiring synchronization
- A tree, a list with hierarchy, with presumably operations requiring synchronization
Tree, a list with hierarchy
Studying the concept of tree with ologs, results in the author’s worldview, in the following diagrams:
The olog states:
-
Adding a special
parentproperty (which is alist item) to alist itemturns a list into a tree-
Notes on
childrenvsparent:-
Having ologs suggest using
parentinstead ofchildrenfeels both intuitive and relieving. In this case, ologs propose a simpler approach, even if it goes against the mainstream. -
The common approach to transforming a list into a tree is
by adding a
childrenproperty, which increases code complexity. However, using aparentproperty is sufficient for UIs, where we typically handle only a few thousand nodes.-
According to Claude AI, the performance difference between parent-only vs
parent+children would only start mattering with:
- Many thousands of nodes
- Very frequent tree operations
- Heavy concurrent access
- Mobile/low-power devices
- Real-time requirement
-
According to Claude AI, the performance difference between parent-only vs
parent+children would only start mattering with:
-
Having ologs suggest using
-
Notes on
-
Tree has, again, very specific operations
-
If we check the
duplicateoperation we’ll see that duplicating a tree item involves duplicating the item itself, and, recursively duplicating all children—which is a synchronization operation
-
If we check the
We need this here because of Tufte ...
List, lists, tree — Variations of a concept
After three attempts to understand the variations of the same concept, a pattern begins to emerge:
- With a simple list item, we have standard CRUD-like operations and a well-defined concept.
- When a list item contains another list, some operations require synchronization.
- When a list item is recursive (forming a tree), some operations require synchronization.
On the other hand, the following observations emerged:
- The olog, the structure is relative stable
- The
list itemis changing, evolving - Complex list items can introduce complex operations that require synchronization
To conclude, and resolve the uncertainty, we can say:
- There are three different but closely related concepts, each determined by the structure and nature of the list item
- While some concepts appear to involve actions that resemble synchronizations, these actions affect the concept itself rather than external concepts, so they are not considered apps.
Let's define the concepts with a focus on their name and purpose, rather than their state and actions, which are still unclear.
concept list
purpose
to provide operations on a collection
state
... # Simple list items
actions
... CRUD-like
principles
??? # This will be tackled once the state and actions are defined
concept lists
purpose
to provide operations on collections
state
... # A list of lists
actions
... # CRUD-like
... # More complex actions involving multiple steps, wrapped into a single atomic transaction
principles
??? # This will be tackled once the state and actions are defined
concept tree
purpose
to provide operations on a hierarchical collection
state
... # A recursive list item
actions
... # CRUD-like
... # More complex actions involving multiple steps, wrapped into a single atomic transaction
principles
??? # This will be tackled once the state and actions are defined
Likely-correct behavior with finite state machines
Now that we have defined the name and purpose of the concepts, the next step is to clarify their state, actions, and principles. This will complete the formalization process and decide whether the three concepts are truly standalone.
Formalizing behavior means formalizing state.
To achieve this, we use Stately.ai/XState, an FSM implementation where Stately provides an online visual state designer, and XState provides the associated state machine code.
This approach is particularly convenient because the XState code closely resembles a concept from concept design, which makes it easy to relate the results back to the previous chapter.
Templates
Instead of presenting the lengthy formalization details for these three concepts—each with a dozen operations—we will present three templates used to formalize them.
While Stately/XState has a broader scope, it provides methods to represent actions, concepts, and synchronizations from concept design through specialized machines.
These machines, presented below as Stately diagrams, serve as templates and can be used to formalize any other concepts and applications.
-
The action machine executes a single operation,
responds to no events, and ends in a final state (either success or
error).
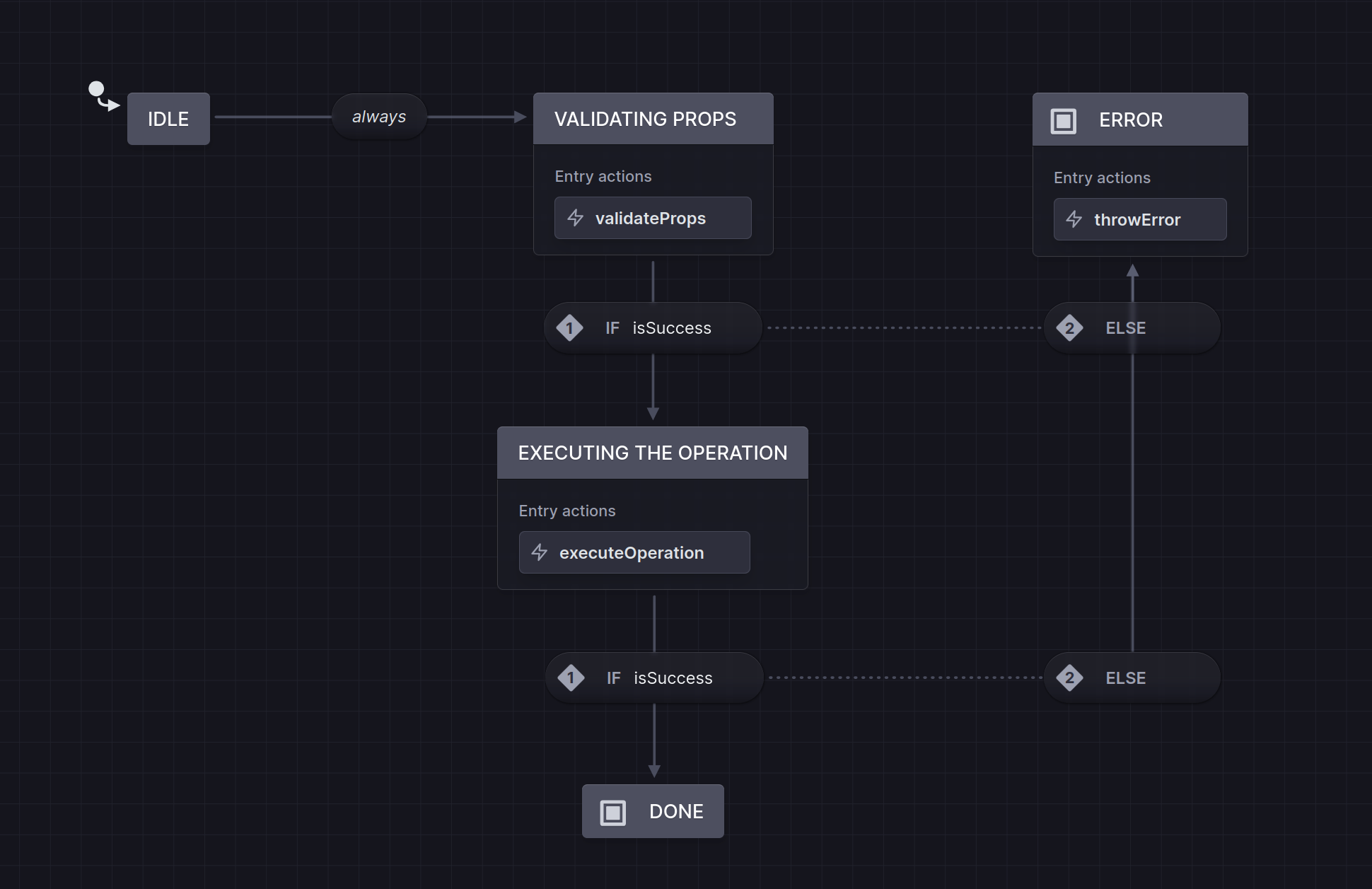
The finite-state machine diagram of an operation / action When invoked, the machine immediately (
always, with no event needed to trigger it) executes the first step of the operation (validating props) and then transitions to the next state. It's like a function call—fire and forget, focusing on the result.Any action of any concept can be built using such a machine.
-
The concept machine imports and invokes the action
machines, responds to events, sets the concept's state, and
transitions back to idle to accept new requests.
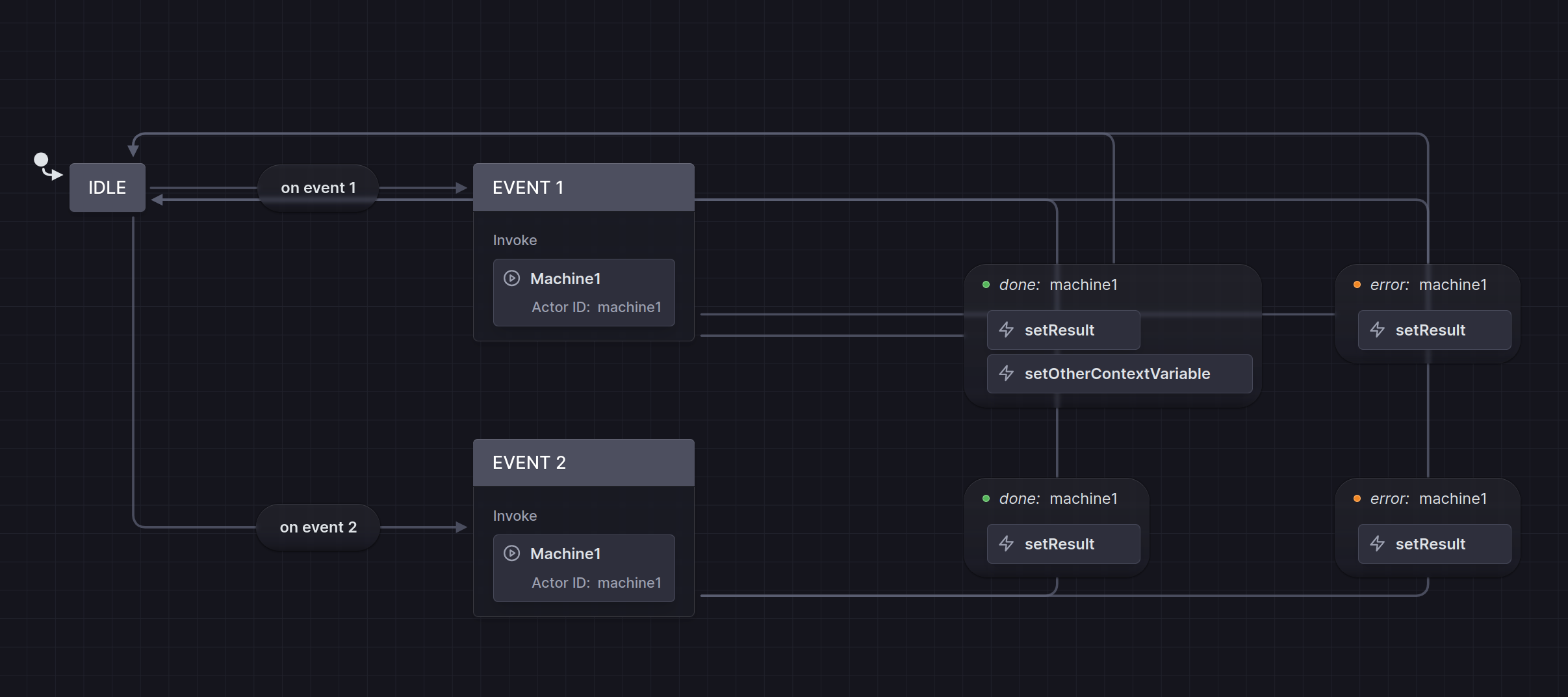
The finite-state machine diagram of a concept When started, the machine enters
idleand waits for an event to occur (e.g.,on event 1,on event 2), which triggers an action (Event 1,Event 2). Each action is an action machine that, when executed, returns either success (done) or error (error). The result of each operation is registered in the machine’s internal memory (the concept’s state) viasetResult, after which the system returns toidle.Any concept can rely on this template. For example, in the case of the list concept, the events could include create, delete, update, and so on.
-
The synchronization machine is a combination of the
two machines described above.
Like an action machine, it responds to no events (starts immediately), performs one task, and ends in a final state.
Like a concept machine, it invokes other machines and sets the global context (the concept’s state) after execution.

A sync machine involving three lists The example above is taken from an online olog editor app and syncs three lists: instances, things and aspects.
Following the atomic transactions recommendation from concept design, it provides a rollback mechanism when an internal operation fails.
We need this here because of Tufte ...
Results
After creating the three concepts with state machines, we can confirm all three concepts are truly standalone, meaning they are valid concepts within concept design.
Moreover, they can be implemented as standalone Typescript/XState libraries with an optional React wrapper, making them useful for both back-end and front-end development.
src/lib/list/
├── list
│ └── functions
│ ├── listMachine.ts # The concept machine
│ └── list.ts
├── listItem
├── listItemBatchCreate
│ ├── listItemBatchCreateMachine.ts # One of the action machines
│ └── listItemBatchCreate.ts
├── listItemBatchDelete # Every operation has its own action machine
├── listItemBatchRead
├── listItemBatchUpdate
├── listItemCreate
├── listItemDelete
├── listItemDuplicate
├── listItemFilter
└── listItemUpdate
src/components/list/
├── ListDemo.tsx
├── ListError.tsx
├── ListItemBatchCreate.tsx
├── ListItemBatchDelete.tsx
├── ListItemBatchUpdate.tsx
├── ListItemCreate.tsx
├── ListItemDelete.tsx
├── ListItemDuplicate.tsx
├── ListItemFilter.tsx
├── ListItemOps.tsx
├── ListItemsOps.tsx
├── ListItemsRead.tsx
├── ListItem.tsx
├── ListOps.tsx
├── ListProvider.tsx
├── List.tsx
└── setContext.ts
When using state machines, the state of a concept is clearly defined by the return types of its actions.
export interface TList<T extends TListItem> extends TListItem {
// The majority of operations returns list items
items?: T[];
// Read, validation returns a single list item
currentItem?: T;
// Batch operations usually works with these special list items
filteredItems?: T[];
filteredItemsIds?: string[];
}
In state machine code the actions are self-contained and pluggable. They follow the Single Responsibility Principle, meaning each action is responsible for its own functionality, making them easily replaceable and modifiable.
src/lib/list/listItemCreate/
├── listItemCreateEvent.ts # The operation / action / machine props
├── listItemCreateMachine.ts # The action machine
└── listItemCreate.ts # The algorithm to append a new item to the items
The machine's operational principles are encoded through state transitions and guards. These principles are extracted by AI and presented in Appendix 3.
Demo
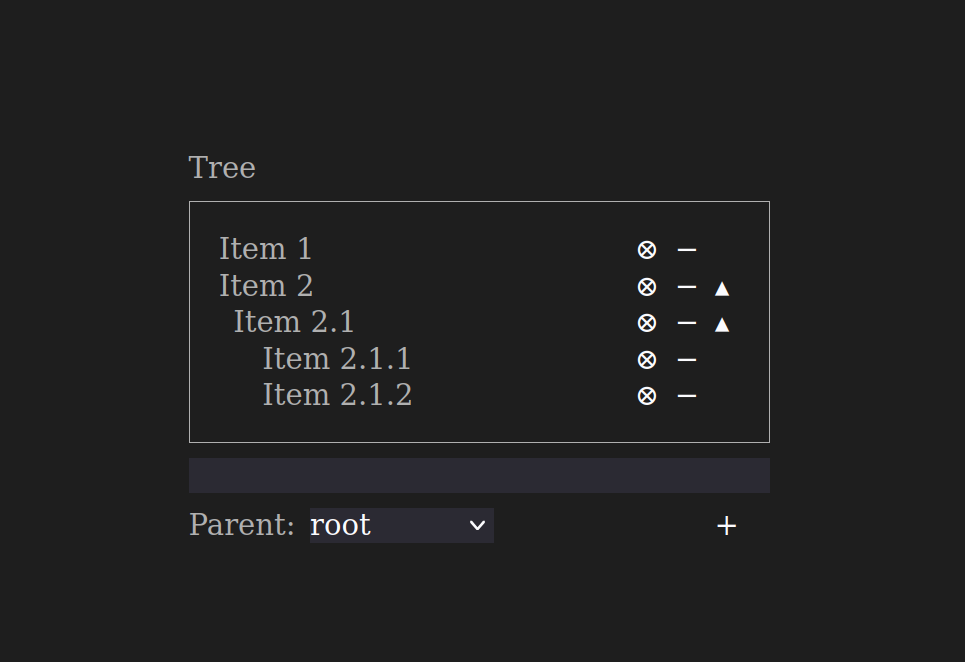
While figuring out the behavior, a small demo app was created featuring all three concepts: the list, the list of lists, and the tree.
More specifically, the list of lists was combined with the list, allowing both lists and their content to be managed together on a single screen.
Implementation and verification with XState
While implementation and verification are not the explicit goals of the study itself, it would be straightforward to detail how the concepts were developed and tested using Stately/XState, leading the author to believe the results are likely correct
Finite state machines are a formal method, meaning they are mathematically grounded and can be provably correct.
The Stately.ai/XState FSM implementation used in this study is not a formal method.
While XState implements FSMs, it does not provide built-in tools for formal verification, such as model checking or theorem proving.
What it offers is a graph decorated with handwritten functions.
// The state machine code
export const listItemCreateMachine = setup({
// Handwritten functions
actions: {},
guards: {},
}).createMachine({
// The state graph as designed in Stately
states: {},
});
Exhaustiveness checking applied to the graph can assure total correctness, and property-based testing applied to the handwritten functions can assure partial correctness, making XState likely-correct.
Likely-correct state
The graph describes the behavior of a concept: all its states and state transitions. It is testable via a simple path generator, which, while it’s not a complete exhaustiveness checker, ensures:
- All reachable states can actually be reached
- Transitions work as expected
- The machine behaves correctly along each possible path
Let’s call this likely-correct state.
Likely-correct code
The graph makes references, meaning it calls and executes handwritten
code (such as isSuccess, validateProps).
"VALIDATING PROPS": {
always: [
{
target: "EXECUTING THE OPERATION",
guard: {
type: "isSuccess",
},
},
{
target: "ERROR",
},
],
entry: {
type: "validateProps",
},
},
Once these plain (TypeScript) functions are fully tested, preferably with property-based testing, we can consider them likely-correct.
Analysis
We started this journey with a big aspiration, rather than just a simple question:
Can we create a list component upon which we can easily build user interfaces?
In other words, we set the goal to develop a user-facing list component that is both generic and, hopefully, likely-correct.
We knew we couldn't build a generic list from scratch, so we adopted an incremental, step-by-step approach, focusing on the first step, which provides a sound foundation and methods whose deliverables are data, enabling rapid iteration.
As a result we have a list concept whose structure and behavior were crafted using formal methods: ologs and finite state machines. We can confidently say that the design of the list is likely-correct.
Additionally, the code supporting the design and architecture was made likely-correct by enhancing the non-formal technology Xstate.
Throughout the process, we have used various formal and semi-formal methods for all tasks. These methods are briefly introduced in the Appendix 1, with their implementation explained throughout the document.
On misses and chapters where we could do better:
Regarding rapid iteration, the theory is available in these slides, but it was not covered in detail in this study. In practice, however, we were able to quickly iterate from the list concept to the lists and tree concepts.
We missed the opportunity to better present how we design and analyze operations; this is still a work in progress
We could have distilled proper concept definitions from the existing code ourselves, but instead, we asked AI to do it. The results can be found in Appendix 3.
Conclusion
It’s relieving and refreshing to create software with these new methods.
It’s less about writing code and more about thinking—understanding the problem—and using novel tools like the olog editor, the Stately editor, graph exhaustiveness testing, property and model-based testing, and more.
It’s also reassuring to prioritize correctness above all else. In the age of rapid software development, speed is a given; what comes next is quality.
As the next steps, to further enhance the likely-correctness of the software, the phases in the process—currently managed by the scientific method—should be better connected through a more formal approach, such as executable specifications.
Once the process is formalized, code generators can be integrated at each step to facilitate rapid iteration. For example, the component structure can be generated from the olog diagrams, and the app state can be generated from the FSM diagrams. The ultimate goal is to reach a point where diagrams become code.
Resources
- Ologs: a categorical framework for knowledge representation — Arxiv, February 2011
- Concept Design — The Essence of Software, Princeton University Press / November 2021
- Finite-state machines — Wikipedia
- Formalism, correctness, cost — Osequi, 2023
- Rapid iteration — Osequi, 2023
- Likely-correct software — Osequi, 2023
- Ontology, taxonomy, choreography — Metamn, October 2019
- Kris Brown: Scientific and software engineering examples of applied category theory — Topos Institute, June 2023
- E.Subrahmanian & Y.Keraron: Engineering practice and the potential role of CT in systems engineering — Topos Institute, December 2024
- Using Lightweight Formal Methods to Validate a Key-Value Storage Node in Amazon S3 — Amazon Science, 2021
- Formal Methods: Just Good Engineering Practice? — Brooker, April 2024
- Property-Based Testing for the People — University of Pennsylvania, January 2024
- Design in practice — Rich Hickey, May 2023
- Where Should Visual Programming Go? — Tonsky, July 2024
- The Osequi Method - List — Demo App, December 2024
About the author
The author holds a degree in mathematics and computer science. He is a self-taught UX/UI designer with works featured in online galleries.
Recently, he has been running a research and development studio specializing in software correctness and rapid iteration, providing consulting services to companies.
Credits
This document was created using Notion and published using a modified version of Tufte CSS.
Appendix 1 — The methods
The scientific method
Software development is fundamentally about problem-solving, yet many teams rely on ad-hoc practices rather than adopting a structured methodology.
- Observations—user needs, system failures—are often undocumented or vague.
- Hypotheses—design decisions, performance assumptions—are rarely stated explicitly.
- Experimentation—prototypes, A/B tests—is conflated with implementation, leading to wasted effort.
- Analysis—postmortems, benchmarks—is reactive rather than proactive.
For structured problem-solving there is the scientific method—a quasi-universal approach that provides a straightforward workflow, which when followed, ensures a complete thought process that is reproducible, reusable, and correctable by peers.
](./images/The_Scientific_Method.svg)
This study employs the scientific method to guide the entire creation process, much like a project management tool.
For a more specific method, tailored to software development, please refer to Rich Hickey’s Design in Practice.
Ontology logs
The State of JS 2023 survey identifies code architecture—organizing and maintaining code—as the top pain point for front-end developers.
This struggle stems from:
-
Inconsistent mental models: One engineer’s
listis another’scollection, leading to fragmented implementations. -
Leaky abstractions: Components like
<AutoComplete>or<DataGrid>grow unwieldy as requirements evolve. -
Ontological drift: The domain model (e.g.,
user profile) morphs over time without documentation.
These issues arise from a lack of shared, precise definitions for foundational concepts. It isn’t just about code—it’s about failing to agree on what things are.
Abstraction distills concepts to their essential properties. When done rigorously—using tools like category theory—it reveals universal structures that are independent of implementation details. This makes abstraction the “most likely true” representation of a system, as it aligns with fundamental truths rather than transient patterns.
On the other hand, ontology is the study of what something is—the nature of a given subject.
Ologs (ontology logs), as a field of Applied Category Theory, serve as a bridge between abstraction and ontology. They are category-theoretic models for knowledge representation, recording the results of ontological studies and providing a rigorous framework for understanding the essence of concepts.
Ologs:
- Define what something is (e.g., “A list is a linearly ordered collection of items”).
- Encode relationships between concepts (e.g., “A list has many list items”).
Concept design
Concept design is a lightweight, semi-formal UX/UI design method ideal for experimentation and communication with stakeholders.
Its building blocks are concepts—standalone entities—and apps which synchronize different concepts.
concept Auth
purpose
to provide an authorization mechanism
state
username: User -> one Text
password: User -> one Text
actions
register (n, p: Text, out u: User)
authenticate (n, p: Text, out u: User)
changePassword (u: User, p: Text)
delete (u: User)
app Zoom
includes
let U = [Auth.User], M = Meeting [U],
C = Chat [U], K = Capability [M].Key
au: Auth
ca: Capability [M]
ch: M -> lone C
syncs
createMeeting (host: U, out k: K, out m: M)
M.new (host, m)
ca.allocate (m, k)
startMeeting (host: U, k: K, out m: M)
ca.get (k, m)
m.start (host)
C.new (c)
m.ch := c // replaces on restart
c.join (host)
postInChat (m: M, u: U, t: Text, out p: C.Post)
m.ch.post (u, t, p)
While ologs formalize the structure of a concept, concept design investigates how a concept behaves in an user-facing environment.
This is an important step. Ologs provide a theoretical structure, concept design provides user interface-specific enhancements.
Finite state machines (FSMs)
The same State of JS 2023 survey highlights managing global state in complex applications as the second biggest pain point for front-end developers.
This struggle manifests as:
- Spaghetti state: Uncontrolled mutations and side effects make debugging a nightmare.
- Race conditions: Asynchronous updates (e.g., API calls) lead to unpredictable behavior.
- Brittle abstractions: Ad-hoc solutions (e.g., Redux reducers) fail to scale with application complexity.
Finite state machines provide a formal, structured approach to state management by:
- Defining states explicitly: Every possible state is enumerated upfront.
- Enforcing transitions: Only valid state changes are allowed.
- Handling side effects predictably: Actions (e.g., API calls) are tied to specific states, eliminating race conditions.
Connecting to ologs, FSMs and ologs are complementary tools. Together, they provide a complete framework for managing complexity: ologs ensure everyone agrees on the what, FSMs ensure everyone agrees on the how.
Appendix 2 — The process and the roles
There are many variations and implementations of the software development process (SDLC) and information architecture design (IA). At the same time there are various roles covering different aspects of the entire process.
To better specify the type of SDLC discussed in this document, we will map its steps to well-known job descriptions. Understanding the skills required for each step will hopefully provide a clear picture of the overall process.
| Step / Aspect |
Structure Data Ontology, taxonomy |
Behavior Application Choreography |
Look and feel Presentation |
|---|---|---|---|
| Understanding | Software Architect | Software Architect | Information Architect |
| Design | Software Architect | Software Architect | UX/UI Designer |
| Implementation | Software Engineer | Software Engineer | Design Engineer |
| Verification | Software Engineer | Software Engineer | Design Engineer |
Appendix 3 — Concept definitions with AI
Far from aiming to maximize the potential of LLMs, this exercise is driven by curiosity: can current, freely accessible LLMs generate concept descriptions from XState code?
Setup
The LLMs used in this experiment are DeepSeek (without Search and DeepThink R1 enabled), Claude 3.5 Sonnet, ChatGPT-4o (without Search and Reason enabled) and Gemini 2.0 Flash.
As input, the LLMs were provided with:
- A simple prompt: “I need to convert XState code to Concept design DSL. I have a document explaining the DSL, and another with the XState code”
- The DSL document which contains a summary of what a concept looks like, along with all the examples from The Essence of Software book.
- A stripped down version of the XState code for the list, lists, and tree machines
Results
ChatGPT and Gemini were out of sync and didn’t fully grasp the problem, while DeepSeek and Claude provided immediate, concise results.
DeepSeek
**concept** list [TListItem]
**purpose**
manage a collection of list items with CRUD and filtering operations
**state**
items: set TListItem
filteredItems: set TListItem
filteredItemsIds: set string
currentItem: TListItem
**actions**
create(newItem: TListItem)
when newItem not in items
add newItem to items
update(newItem: TListItem)
when newItem in items
replace old item with newItem in items
delete(itemId: string)
when itemId in items
remove item with itemId from items
duplicate(itemId: string, newItem: TListItem)
when itemId in items and newItem not in items
add newItem to items
filter(predicate: (item: TListItem) -> bool)
apply predicate to items
store matching items in filteredItems and their ids in filteredItemsIds
batchCreate(newItems: TListItem[])
when newItems not in items
add all newItems to items
batchUpdate(newItems: TListItem[])
when newItems in items
replace old items with newItems in items
batchDelete(ids: string[])
when ids in items
remove items with ids from items
batchRead(ids?: string[])
when ids provided
return items with matching ids
else return all items
**operational principles**
after create(newItem), newItem is in items
after update(newItem), newItem replaces old item in items
after delete(itemId), item with itemId is not in items
after filter(predicate), filteredItems contains items matching predicate
after batchCreate(newItems), all newItems are in items
after batchUpdate(newItems), all newItems replace old items in items
after batchDelete(ids), items with ids are not in items
after batchRead(ids), returned items match ids or all items if no ids provided
**concept** lists [TList]
**purpose**
manage a collection of lists, each containing list items with CRUD operations
**state**
items: set TList
each TList has:
items: set TListItem
currentItem: TListItem
filteredItems: set TListItem
filteredItemsIds: set string
**actions**
createList(listId: string, newList: TList)
when listId not in items
add newList to items
duplicateList(listId: string, newList: TList)
when listId in items and newList not in items
add newList to items
deleteList(listId: string)
when listId in items
remove list with listId from items
createListItem(listId: string, newItem: TListItem)
when listId in items and newItem not in list.items
add newItem to list.items
updateListItem(listId: string, newItem: TListItem)
when listId in items and newItem in list.items
replace old item with newItem in list.items
deleteListItem(listId: string, itemId: string)
when listId in items and itemId in list.items
remove item with itemId from list.items
duplicateListItem(listId: string, itemId: string, newItem: TListItem)
when listId in items, itemId in list.items, and newItem not in list.items
add newItem to list.items
**operational principles**
after createList(listId, newList), newList is in items
after duplicateList(listId, newList), newList is in items
after deleteList(listId), list with listId is not in items
after createListItem(listId, newItem), newItem is in list.items
after updateListItem(listId, newItem), newItem replaces old item in list.items
after deleteListItem(listId, itemId), item with itemId is not in list.items
after duplicateListItem(listId, itemId, newItem), newItem is in list.items
**concept** tree [TTreeItem]
**purpose**
manage a hierarchical collection of tree items with CRUD operations
**state**
items: set TTreeItem
each TTreeItem has:
id: string
name: string
parentId: string | "root"
filteredItems: set TTreeItem
filteredItemsIds: set string
**actions**
create(newItem: TTreeItem)
when newItem not in items
add newItem to items
update(newItem: TTreeItem)
when newItem in items
replace old item with newItem in items
delete(itemId: string)
when itemId in items
remove item with itemId and all its descendants from items
duplicate(itemId: string, newItem: TTreeItem)
when itemId in items and newItem not in items
add newItem to items
**operational principles**
after create(newItem), newItem is in items
after update(newItem), newItem replaces old item in items
after delete(itemId), item with itemId and its descendants are not in items
after duplicate(itemId, newItem), newItem is in items
Claude
**concept** List [T: ListItem]
**purpose**
Manage a flexible collection of items with create, update, delete, and filtering operations
**state**
items: set T
currentItem: T?
filteredItems: set T
filteredItemsIds: set String
**actions**
create(newItem: T, checkPresenceOf: set String, checkUniquenessOf: set String)
validate newItem against presence and uniqueness constraints
add newItem to items
update(newItem: T, checkPresenceOf: set String, checkUniquenessOf: set String)
when item exists in items
replace existing item with updated item
delete(itemId: String)
remove item with given id from items
duplicate(itemId: String, newItem: T, checkPresenceOf: set String, checkUniquenessOf: set String)
create new item based on existing item
ensure unique properties
filter(predicate: Func<T, Boolean>)
update filteredItems with items matching predicate
update filteredItemsIds with ids of filtered items
batchCreate(newItems: set T, checkPresenceOf: set String, checkUniquenessOf: set String)
for each item in newItems
create(item, checkPresenceOf, checkUniquenessOf)
batchUpdate(newItems: set T, checkPresenceOf: set String, checkUniquenessOf: set String)
for each item in newItems
update(item, checkPresenceOf, checkUniquenessOf)
batchDelete(ids: set String)
for each id in ids
delete(id)
batchRead(ids?: set String): set T
return items, optionally filtered by specified ids
**operational principles**
batch operations affect multiple items efficiently
each create operation ensures unique identifiers
update preserves item's fundamental identity
filtering provides flexible item selection
duplication creates a distinct, new item
operations maintain list integrity and consistency
**concept** Lists [ListItem]
**purpose**
Manage multiple lists where each list is itself a list item
**state**
items: set List<ListItem>
**actions**
create(listId: String, newItem: ListItem, checkPresenceOf: set String, checkUniquenessOf: set String)
when list with listId exists
add newItem to list's items
update(listId: String, newItem: ListItem, checkPresenceOf: set String, checkUniquenessOf: set String)
when list with listId exists
update item in list's items
delete(listId: String, itemId: String)
when list with listId exists
remove item from list's items
duplicate(listId: String, itemId: String, newItem: ListItem, checkPresenceOf: set String, checkUniquenessOf: set String)
when list with listId exists
create copy of item in list's items
createList(newItem: ListItem, checkPresenceOf: set String, checkUniquenessOf: set String)
add new list to items
deleteList(listId: String)
remove list from items
duplicateList(itemId: String, checkPresenceOf: set String)
create copy of list in items
**operational principles**
lists can contain other lists
each list maintains its own items
operations on items target specific list
list operations maintain hierarchy
**concept** Tree [Item]
**purpose**
manage hierarchical items with parent-child relationships
**state**
items: set Item
parentId: Item -> one (Item + "root")
result: optional Result
**actions**
create(newItem: Item)
when newItem not in items
when all required fields present
when all fields unique
add newItem to items
set newItem.parentId
update(newItem: Item)
when newItem in items
when all required fields present
when all fields unique
update newItem fields
update newItem.parentId
delete(itemId: Item)
when itemId in items
remove itemId from items
remove all descendants of itemId from items
duplicate(itemId: Item, newItem: Item)
when itemId in items
when newItem not in items
when all required fields present
when all fields unique
copy itemId to newItem
add newItem to items
**operational principles**
after create(item), item and its parent exist in items
after delete(item), item and its descendants are removed
after update(item), item reflects new values while maintaining hierarchy
after duplicate(item, newCopy), both exist with same structure
Analysis and conclusion
Since we don’t have an exact definition or grammar for the Concept Design DSL, the results cannot be formally verified.
For the author, the results look good, closely reflecting the
functionality in the code. What code has in plus is
synchronizations—complex actions like
duplicate performing atomic transactions—but these were
removed from the prompt, because synchronizations belong to apps in
concept design.
A pleasant surprise is how Claude created—re-invented the format for—the operational principles in list and lists. These short sentences (”lists can contain other lists”, “each list maintains its own items”) remind the facts from the olog (”A list item always belongs to a single list”).
If, in the future, by maximizing the potential in LLMs, the olog can be connected to concept design in such an elegant way, then we can achieve a complete synchronization between these methods.
Furthermore, with a well-tuned LLM, the DSL-to-XState translation becomes possible. In this scenario, code writing is eliminated from the process, once again leading to the "diagrams are code" paradigm.